When talking to clients, engineers, and owners about the powerful benefits of tagging and data modeling, the question ultimately comes up “So how do I get tagged data into my system and isn’t a lot of work?” A fair question and concern, particularly coming from the perspective of traditional software tools and techniques that historically are very labor intensive, and the perception that additional configuration/engineering is required. I’ll address this topic first conceptually by describing the options and approaches to add metadata to a project; then I will get more specific with an example of a toolset and workflows that are leveraged in a typical FIN framework-based project.
Where do tags live?
First, the basics. In order to gain the full benefits from a tagged system (as I outlined in my previous white paper Strategy and Payoffs of Meta-Data Tagging), the foundational concept is that data from the connected world must be “self-describing” in order for software applications to “just work.” Simply put, the database needs to contain the tags and conform to standard data models (as described in the open source initiative, Project Haystack). Let’s look first at where tags can exist in some typical architectures and use cases:
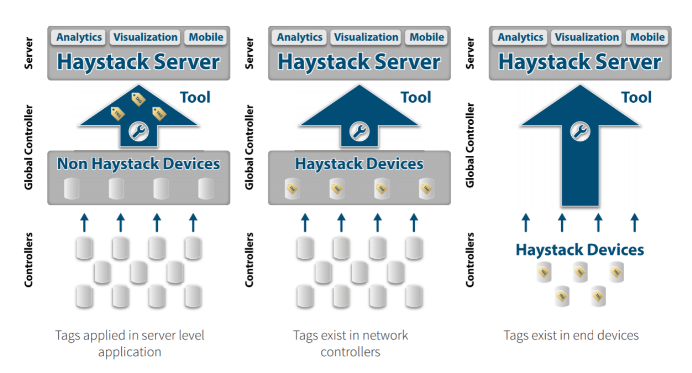
Much of the connectable world already exists as legacy systems comprised of global and device level controllers, therefore tags need to be applied at the server level. This can happen using a variety of tools and techniques (which I’ll detail a bit latter), generally during the database creation phase of a project.
As more manufactures come to market with their devices modeled and data already documented with Haystack tags, the ability to programmatically add devices and associated points becomes fundamentally simpler for tools to accomplish. Typically, at the global or network controller, libraries and templates can be used to dramatically reduce labor needed to build databases for applications to utilize.
Taking it one step further, when more and more products come from manufacturers that natively speak the Haystack protocol at the end device level, we will achieve the holy grail of interoperable and self-describing smart devices! The labor needed to implement solutions becomes nearly zero since the tags exist in the devices, and the data can be simply queried from the applications that need it.
Tools and workflows for tagging
Let’s look now at details of the tools and workflow ramifications of these various architectures. The good news is that there are a lot of options and techniques available to take care of the task of getting a tagged and modeled database. Because of the different architectures and variety of projects, there are multiple tools that can be used along the path to a completed project.
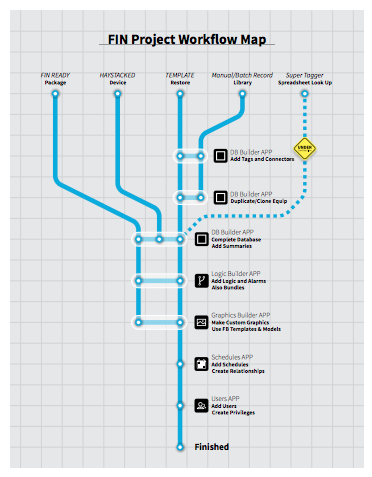 The most common approach when faced with large project of legacy data is what I call the “Super Tagger”. This is a collection of tools and techniques I’ve seen used, ranging from Excel macros to powerful AI scripts. This approach looks at existing point data (typically point names), and tries to work out meaning and relationships. Often the integrator uses an iterative process to look for commonality and repetitive point types, in order to batch edit the tags and refine the database.
The most common approach when faced with large project of legacy data is what I call the “Super Tagger”. This is a collection of tools and techniques I’ve seen used, ranging from Excel macros to powerful AI scripts. This approach looks at existing point data (typically point names), and tries to work out meaning and relationships. Often the integrator uses an iterative process to look for commonality and repetitive point types, in order to batch edit the tags and refine the database.
The next two approaches are very similar in that they can programmatically add tags to the database, dramatically speeding up the process. “Templates and Libraries” take advantage of a well-defined and consistent model at either the point or device level. For example, if data points have been consistently named by a manufacturer of controllers, then a library can quickly be created to add tags based on discovering those points. Even better, if standard applications can be identified, then templates for entire pieces of equipment can be modeled and imported with their tags! Then with power tools such as cloning, duplicate collections of points can be created for each instance of typical equipment.
Finally, when a device is native Haystack (meaning the tags already exist in the device), this “Haystacked device” requires no tools, since with a simple query using the Haystack protocol makes the device data become instantly available! Imagine a world of Haystack devices and servers that seamlessly share device data with applications, no extra work required!
Taking it to another level
One final thought, we could take the use of tools and templating beyond creating the database, to include other aspects of a typical BAS/IoT solution. By using Open Frameworks, we can both leverage the power of tagging and application specific tools to even further automate the process. Manufacturers now have the ability to deliver “FIN ready” devices that will dynamically: get modeled in the database, create supervisory control logic, provide alarm routines, start collecting historical data, and generate their own graphical user experiences!
Topics from this blog: FIN App Suite
Back to all posts